https 协议的工作原理
- 客户端使用 https 访问服务器,则要求 web 服务器建立 ssl 链接
- web 服务器接收客户端的请求后,会将网站的证书(包含公钥),传输给客户端
- 客户端和 web 服务器端开始协商 SSL 链接的安全(加密)等级
- 客户端浏览器通过双方协商一致的安全等级,建立会话秘钥,然后通过网站的公钥来加密会话秘钥,传送给网站
- web 服务器 通过自己的私钥解密出 会话秘钥
- web 服务器 通过 会话秘钥 加密 与客户端之间通信
TCP 三次握手
- 第一次,建立连接时,客户端**发送 SYN 包(syn=j)**到服务器,并进入
SYN_SENT状态,等待服务器确认;SYN(Synchronize Sequence Numbers,同步序列号) - 第二次,服务器收到 SYN 包并确认客户的 SYN (ack=j+1),同时也发送一个自己的 SYN 包(syn=k), 即 SYN+ACK 包,此时服务器进入
SYN_RECV状态 - 第三次,**客户端收到服务器的 SYN+ACK 包,向服务器返送确认包 ACK(ack=k+1)**,此包发送完毕后,客户端和服务器进入
ESTABLISTHED状态,完成三次握手
TCP 四次挥手
- 客户端进程发出连接释放报文,并停止发送数据。释放数据报文首部,FIN=1,其 seq=u(等于前面已经出过来的数据的最后一个字节序号+1),此时,客户端进入
FIN_WAIT_1(终止等待1)状态。 - 服务端收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并带上自己的序列号 seq=v,此时,服务器进入
CLOSE_WAIT状态。TCP 服务器通知高层的应用进程,客户端向服务器的方向已释放,这时处于半关闭状态,即 客户端已经没有数据要发送,但服务器若发送数据,客户端仍然要接受。 - 客户端收到服务器的确认报文后,此时,客户端进入
FIN_WAIT_2状态,等待服务器发送连接释放报文,在这之前还需要接受服务器发送的最后的数据 - 服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的 seq=w, 此时,服务器进入
LAST_ACK状态,等待客户的确认。 - 客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,自己的 seq=u+1,此时,客户端就进入
TIME_WAIT状态。此时 TCP 连接还没有释放,必须等待一段时间后,当客户端撤销相应 TCB 后,进入CLOSED状态。 - 服务器只要收到客户端发出的确认,立即进入
CLOSED状态,撤销 TCB 后,就结束了 TCP 连接。
TCP/IP 如何保证数据包传输的有序可靠?
对字节流分段并进行编号,然后通过 ACK 确认回复 和超时重发 机制来保证
- 为了保证数据包的可靠传递,发送方把已经发送的数据包保留在缓冲区
- 并为每个已发送的数据包启动一个超时定时器
- 如果在定时器超时之前收到对方的应答信息,则取消定时器,释放数据包占用的缓冲区
- 否则,重传该数据包,直到收到应答 或 重传次数超过最大次数为止
- 接收方收到数据包后,进行 CRC 校验,正常则将数据交给上层协议,然后给发送方 发送一个累计应答包,表明该数据已收到。如果接收方正好也有数据要发给发送方,应答包也可在数据包中捎带过去。
TCP 和 UDP 的区别
- TCP 是面向连接的,UDP 是无连接的
- TCP 仅支持单播传输,UDP 提供了单播、广播、多播的功能
- TCP 的三次握手保证了连接的可靠性,UDP 是无连接的,不可靠的,对接收的数据不发送确认信号,发送端也不知道数据是否正确接收
- UDP 的头部开销比 TCP 的更小,数据传输速率更高,实时性更好
cookie、sessionStorage、localStorage
cookie 数据大小不能超过 4K,sessionStorage、localStorage 的存储大,5M+
cookie 设置的过期时间之前一直有效; localStorage 永久存储,浏览器关闭后数据不丢失,除非主动删除;sessionStorage 数据在当前浏览器关闭窗口后自动删除
cookie 数据会自动传递到服务器;sessionStorage、localStorage 数据保存在本地
粘包问题分析、对策
TCP 是面向流的协议,粘包问题主要是因为接收方不知道消息之间的界限,不知道一次提取多少字节的数据造成的。而 UDP 是面向消息的协议,每个 UDP 都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据。
TCP 为了提高传输效率,发送方往往要收集到足够多的数据后才发送一个 TCP 段。TCP 会使用优化方法,将多次间隔较小且数据量小的数据,合并成一个大的数据块发送出去,这样接收方就难于分辨。
- 发送方需要等待缓冲区满才发送,造成粘包
- 接收方不及时接收缓冲区的包,造成多个包接收
粘包有两中情况:粘在一起的包都是完整的数据包,粘在一起的包有不完整的包
比较周全的对策:接收方创建一预处理线程,对接收到的数据包进行预处理,将粘连的包分开
从输入 URL 到页面加载的全过程
传送门 # DNS 域名解析过程, # 浏览器的工作原理
- 浏览器输入 url
- 查找缓存:浏览器先查看浏览器缓存->系统缓存->路由缓存中是否有该地址页面,如果有则显示该页面内容,没有,进行域名解析,也是先查看缓存
- 浏览器缓存:浏览器会记录 DNS 一段时间
- 操作系统缓存:如果浏览器缓存中不包含这个记录,则会获取操作系统的记录(其保存最近的 DNS 查询缓存)
- 路由器缓存:如果上述两步均不能成功获取 DNS 记录,则继续搜索路由器缓存
- ISP 缓存: 若上述都失败,继续向 ISP 搜索
- DNS 域名解析:浏览器向 DNS 服务器发送请求,解析该 URL 中域名对应的 IP 地址。使用 UDP 协议
- 建立 TCP 连接: 解析出 IP 地址,和服务器建立 TCP 连接(3 次握手)
- 发起 HTTP 请求: 浏览器发送 http 请求
- 服务器响应: 服务器对浏览器请求做出响应,并把对应 html 文件发送给浏览器
- 关闭 TCP 连接:4 次挥手
- 浏览器渲染:浏览器解析 html 内容并渲染
- 构建 DOM 树: 词法分析然后解析成 dom 树
- 构建 CSS 规则树
- 构建 render 树: web 浏览器将 DOM 和 CSSOM 结合,并构建出渲染树
- 布局(Layout):计算每个节点在屏幕中的位置
- 绘制(Painting):变量 render 树,并使用 UI 后端层绘制每个节点
- JS 引擎解析:调用 js 引擎执行 js 代码(js 解释阶段、预处理阶段、执行阶段生成执行上下文,VO,作用域链,回收机制)
- 创建 window 对象: window 对象(全局执行环境),当页面产生时就被创建,所有的全局变量和函数都属于 window 的属性和方法,而 DOM 树 会映射到 window 的 document 对象上。关闭网页时,全局执行对环境被销毁
- 加载文件: js 引擎分析语法、词法是否合法,合法进入预编译
- 预编译:在预编译过程中,浏览器会寻找全局变量声明,把它作为 window 的属性加入到 window 对象,并给变量赋值为“undefined”;寻找全局函数声明,把它作为 window 的方法加入到 window 对象,并将函数体赋值给它。
- 解释执行: 执行到变量就赋值,如果变量没有被定义(即没有别预编译就直接赋值),在 es5 非严格模式下此变量会成为 window 的一个属性。函数执行,就将函数的环境推入一个环境的栈中,执行完成后再弹出,控制权交互给之前的环境。
浏览器重排、重绘
重排、重绘区别?
- 重排/回流(Reflow), 当 DOM 的变化影响到了元素的的几何信息,浏览器需要重新计算元素的集合属性,在将其摆放在页面正确的位置,这一过程即使重排。重新生成布局,重新排列元素。
- 重绘(Repaint), 元素的外观属性发生变化,但没有改变布局,即重新将元素外观绘制出来的过程。
如何触发重排、重绘?
任何改变用来构建渲染树的信息都会导致一次重排或重绘
- 添加、删除、更新 DOM 节点
display:none,触发重排和重绘display:hidden, 只触发重绘,因为无几何变化- 移动或给 DOM 节点添加动画
- 添加一个样式表、调整样式属性
- 用户行为,调整窗口大小、改变字号、滚动
如何避免重排、重绘?
- 集中改变样式,而非一条条地修改 DOM 样式
- 万万不可把 DOM 节点的属性值放置于循环中当作变量
- 为动画的元素 设置
position为fixed或absolute, 这样修改其 CSS 不会重复 reflow - 尽量只修改
position为fixed或absolute的元素,这对其它元素影响不大 - 尽量不使用 table 布局,因为一个很小的变动可能造成整个 table 的 reflow
- 动画开始 GPU 加速,translate 使用 3D
- 提示为合成层
- 合成层的位图,会交由 GPU 合成,比 CPU 处理的要快
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他层
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint
- 使用 CSS 的
will-change属性
浏览器缓存机制
缓存过程分析
浏览器和服务器通信的方式 为应答模式,即浏览器发送 http 请求 - 服务器响响应请求。
浏览器第一次向服务器发送请求并得到响应结果,会根据响应报文中 http 头中的缓存标识,决定是否缓存响应结果,是否将响应结果和缓存标识存入浏览器缓存中。
- 浏览器每次请求,都会 先在浏览器缓存中查找该请求的结果和缓存标识
- 浏览器每次拿到返回的请求结果都会 将该结果和缓存标识存入浏览器缓存中
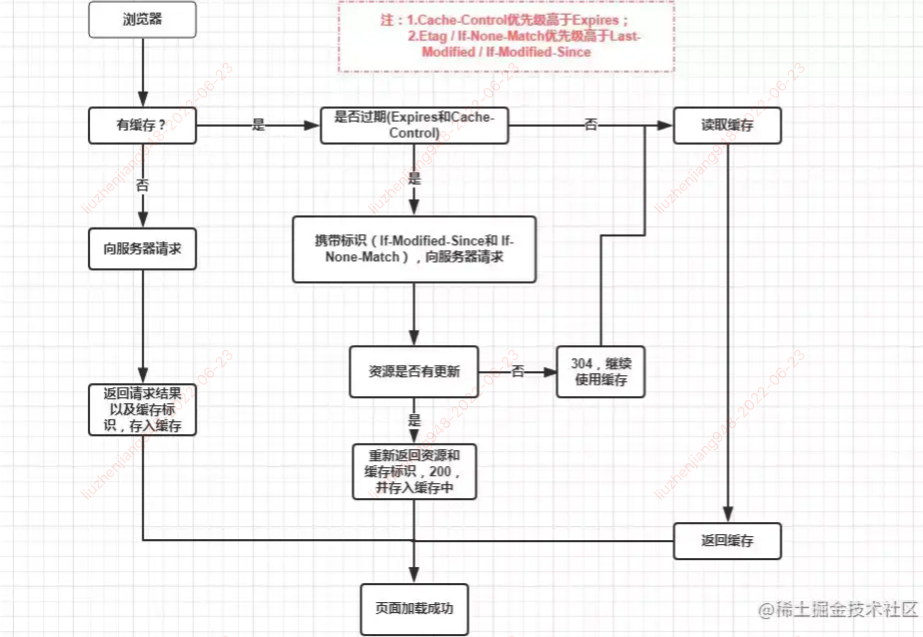
强制缓存
向浏览器缓存查询请求结果,并根据该结果的缓存规则来决定是否使用,3 中情况
- 不存在该缓存结果和缓存标识,强制缓存失效,则直接向服务器发起请求
- 存在该缓存结果和 缓存标识,但结果失效,强制缓存失效,则使用协商缓存(携带该资源的缓存标识、发起 http 请求)
- 存在改缓存结果和缓存标识,且结果尚未失效,强制缓存生效,直接返回该缓存结果
控制强制缓存的字段 Expires(http1.0) 和 Cache-Control (http 1.1), 其中 Cache-Control 优先级较高
- Expires , 缓存的到期时间,小于此时间,直接使用缓存结果, (客户端、服务端时间不一致)
- Cache-Control,主要取值
- public, 所有内容都将被缓存(客户端、代理服务器都可缓存)
- private, 默认值 所有内容 只有客户端缓存
- no-cache, 客户端缓存内容,是否使用缓存,需要经过协商缓存来验证决定
- no-store,所有内容都不被缓存
- max-age=xxx, 缓存内容将在 xxx秒后失效
强制缓存存放的位置
- from memory cache (内存缓存), 快速读取、时效性。 将编译解析后的文件,直接存入该进程的内存中,占据该进程一定的内存资源,一旦进程关闭,则改进程的内存会清空。
- from disk cache (硬盘缓存), 将缓存写入硬盘文件,读取缓存时需要对进行 I/O 操作,然后重新解析该内容,速度比内存缓存慢。
协商缓存
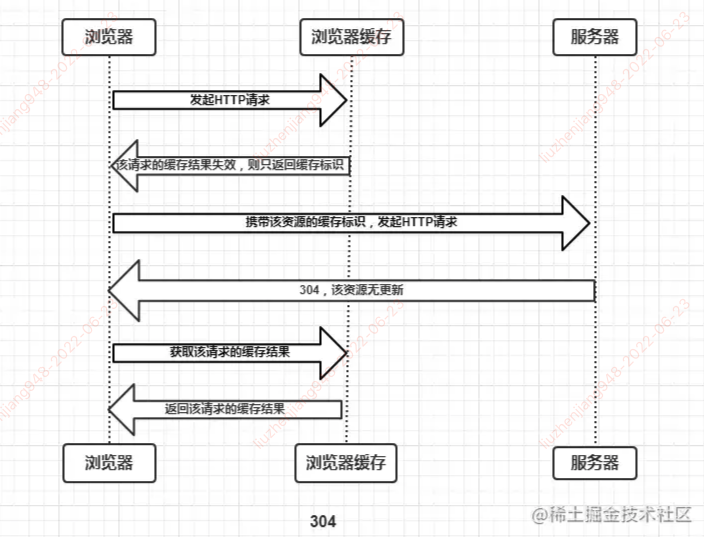
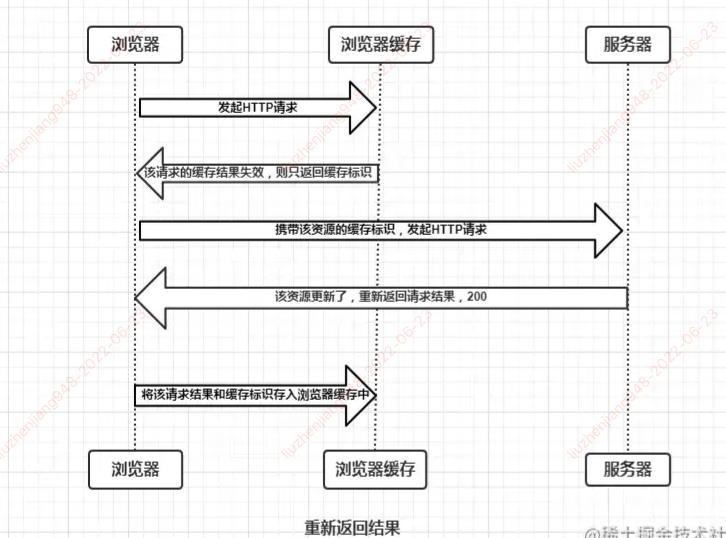
在强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程, 2 中情况
协商缓存生效,返回 304
协商缓存失效,返回 200 和请求结果
控制协商缓存字段 Last-Modified / If-Modified-Since 和 Etag / If-None-Match, 其中 Etag / If-None-Match 优先级较高
- Last-Modified / If-Modified-Since
- Last-Modified, 服务器响应请求时,返回该资源文件在服务器最后被修改的时间
- If-Modified-Since, 客户端再次发起请求时,携带上次请求返回的 Last-Modified 值,通过此字段告诉服务器该资源上次请求返回的最后修改时间。服务器收到该请求,会根据 If-Modified-Since 字段值与该资源在服务器的最后修改时间做对比,若服务器的资源最后修改时间大于 If-Modified-Since 字段值,则重新返回资源,状态码 200; 否则返回 304,代表资源无更新,继续使用缓存文件
- Etag / If-None-Match
- Etag, 服务器响应请求是,返回当前资源文件的唯一标识( 由服务器生产)
- If-None-Match,客户端再次发起请求时,携带上一次请求返回的唯一标识 Etag 值,通过此字段值告诉服务器该资源上次请求返回的唯一标识值。服务器收到该请求后,会与该资源在服务器的 Etag 值做对比,一致则返回 304 Not Modified,代表资源无更新,可继续使用缓存文件;不一致则重新返回资源文件,状态码 200
总结
- 浏览器缓存分为强制缓存和协商缓存,强制缓存优先于协商缓存
- 若强制缓存生效(Expires 和 Cache-Control,Cache-Control 优先级高),直接使用缓存
- 若强制缓存不生效,则进行协商缓存(Last-Modified/If-Modified-Since, Etag/If-None-Match, Etag/If-None-Match 优先级高), 协商缓存由服务器决定是否使用缓存
- 若协商缓存失效,代表请求的缓存失效,重新换取请求资源,返回 200,在存入浏览器缓存;
- 若协商缓存生效,返回 304, 可继续使用缓存
BFC(块级格式上下文)
BFC 是 Block Formatting Context 的缩写,即块级格式化上下文。BFC 是 CSS 布局的一个概念,是一个独立的渲染区域,规定了内部 box 如何布局,并且这个区域的子元素不会影响到外面的元素。布局规则:
- BFC 是一个独立容器,容器里面的子元素不会影响到外面的元素
- 内部 Box 会在垂直方向,一个接一个地放置
- Box 垂直方向的距离由 margin 决定,同一个 BFC 的两个相邻 Box 的 margin 会重叠
- 每个元素的 margin box,与包含块border box 的左边相接触
- BFC 的区域不会与 float box 重叠
- 计算 BFC 的高度时,浮动元素也参与计算高度
- 元素的类型和 display 属性 决定了此 box 的类型,不同 box 类型有不同的 formatting context
如何创建 BFC?
- 根元素,
- float 的值不为 none
- position 为 absolute 或 fixed
- display 的值 为 inline-bloc, table-cell, table-caption
- overflow 的值 不为 visible
元素水平垂直居中?
水平居中
- 行内元素,
text-align:center - 确定宽度的块级元素
- width 和 margin 实现,
margin: 0 auto - 绝对定位和 margin-left:(父 width - 子 width) / 2 ,父元素 position: relative
- width 和 margin 实现,
- 宽度未知的块级元素
display:table+ margin 左右 autodisplay:Inline-block+text-aligin:center- 绝对定位+ transform, translateX 移动本身元素的 50%
- flex 布局 使用
justify-content:center
垂直居中
- line-height, 适合纯文字类
- 父容器 相对定位,子级设置 绝对定位,通过 margin 实现或者 通过 位移 transform
- flex,
- table 布局,父级 display:table, 子级
vertical-align
页面布局
FLex 布局
容器的属性
- flex-direction,主轴方向
- flex-wrap, 换行规则
- flex-flow, flex-direction 和 flex-wrap 的复合属性,
flex-flow: row-reverse wrap; - justify-content, 水平主轴方向的对齐方式
- align-item, 竖直侧轴方向 的对齐方式
- align-content, 容器有多行项目时,垂直方向的对齐方式
元素/项目的属性
- order, 项目的排列顺序,越小越靠前
- flex-grow, 放大比例
- flex-shrink,缩小比例,为 0, 则不缩小
- flex-basis, 设置伸缩基准值(初始长度)
- flex, flex-grow ,flex-shrink, flex-basis 的复合属性, 默认值 0 1 auto
- align-items, 默认 auto,继承父元素
Rem 布局
Rem 是相对于 根元素(html) 的 font-size 大小来计算,其本质是具基于宽度的等比缩放。 缺点:
- 改动多,所有盒子都需要我们去给一个准确的值,才能保证不同机型的适配
- 在响应布局中,必须通过 js 来动态的控制根元素 font-size 大小。css 与 js 有一定的耦合性,且必须将改变 font-size 的代码放在 css 样式之前
百分比布局
子元素的百分比并非完全相对于直接父元素的 height、width。
padding、border、margin 等属性不论是水平 ,还是垂直方向都相对于直接父元素 width
border-width, translate、background-size 则相对于自身
清除浮动
添加标签,设置 clear:both 属性
父级添加 overflow 属性,或设置高度
建立 伪元素 选择器 清除浮动
1
2
3
4
5
6
7
8
9
10
11<div class="parent">
<div style="clear:both"></div>
</div>
.parent::after {
content: "";
display: block;
height: 0;
visibility:hidden;
clear: both;
}
JS 垃圾回收机制
如果存在大量不被释放的内存(堆、栈、上下文),页面性能会变的很慢。当某些代码操作不能别合理释放,就会造成内存泄露
浏览器垃圾回收机制:浏览器的 js 具有自动垃圾回收机制,垃圾收集器会定期的找出那些不在继续使用的变量,然后释放其内存。
标记清除(mark-and-sweep):当变量进入上下文,会被加上存在于上下文的标记。当变量离开上下文时,会被加上离开上下文的标记。 垃圾回收程序运行的时候,会标记内存中存储的所有变量,然后将所有上下文中的变量,以及被上下文中的变量引用的变量的标记去掉,之后再有标记的变量就是待删除的(任何在上下文中的变量都访问不到它们了),随后垃圾回收程序做一次内存清理,销毁带标记的所有值并回收它们的内存。
引用计数:记录每个变量被引用的次数,当一个值的引用数减为 0 时,就会被回收
闭包
在 js 中变量的作用域属于函数作用域,在函数执行完毕后,作用域就会被清理,内存也随之被回收。但是由于闭包函数是建立在函数内部的子函数,由于其可访问上级作用域,即使上级函数执行完,作用域也不会随之销毁,这时的子函数(即闭包),便拥有了访问上级作用域中变量的权限。
闭包形成的条件
- 函数的嵌套
- 内部函数引用外部函数的局部变量,延长外部函数的变量生命周期
闭包的用途
- 模仿块级作用域
- 保护外部函数的变量(阻止其被回收)
- 封装私有变量
- 创建模块
JS 中 this 的五种情况
- 作为普通函数执行时,this 执行 window
- 当函数作为对象的方法被调用时,this 指向该对象
- 当使用 new 来实例化一个构造函数时,this 指向实例
- 箭头函数中 this 是在定义时绑定的,指向它的父级作用域
- 基于 Function.prototype 上的 apply、call、bind 调用,这三个方法都可以显示的指定调用函数的 this 指向
原型&& 原型链
- 每个构造函数都有原型
prototype - 每个实例都有隐式原型
__proto__ - 实例的
__proto__指向构造函数的prototype
new运算符的实现机制
- 创建一个新的空对象
- 设置原型,将对象的原型设置为函数的prototype对象
- 让函数的this指向该对象, 执行构造函数代码(为这个新对象添加属性)
- 如果无返回值或返回一个非对象值,则返回该对象,否则会将返回值作为新对象返回
1 | new Animal('cat') = { |

